
Einführung
„Ich möchte LLMs verwenden, aber die Verwaltung von API-Schlüsseln ist so umständlich…" „Ich möchte keine Benutzereingaben in die Cloud senden…"
WebLLM löst beide Probleme auf einmal.
WebLLM ist eine leistungsstarke Inferenz-Engine, die LLMs direkt im Browser ausführt — vollständig serverlos und ohne Backend. Im Gegensatz zu cloudbasierten KI-Diensten wie ChatGPT oder Claude wird die gesamte Inferenzverarbeitung vollständig auf dem Gerät des Benutzers abgeschlossen.
Dieser Artikel erklärt ausführlich WebLLMs Architektur, Funktionen und Implementierungsmethoden.
Was ist WebLLM?
WebLLM (@mlc-ai/web-llm) ist eine Open-Source-JavaScript-Bibliothek, die vom MLC-AI-Projekt entwickelt wurde. Sie wurde hauptsächlich von Forschern der Carnegie Mellon University, der Shanghai Jiao Tong University und NVIDIA entwickelt und Ende 2024 als Paper "WebLLM: A High-Performance In-Browser LLM Inference Engine" veröffentlicht.
Kurz gesagt:
Ein Framework, das den Browser zu einer Laufzeitumgebung für LLMs macht.
Hauptmerkmale
| Merkmal | Beschreibung |
|---|---|
| 🌐 Vollständig im Browser | Kein Server erforderlich. Keine Installation notwendig |
| 🔒 Datenschutz | Daten verlassen das Gerät nie |
| ⚡ WebGPU-Beschleunigung | Erreicht 70–88% der nativen Performance |
| 🔄 OpenAI-kompatible API | Bestehender Code kann mit minimalen Änderungen wiederverwendet werden |
| 📦 Breite Modellunterstützung | Llama, Phi, Gemma, Mistral und mehr |
Funktionsweise
Der Grund für WebLLMs hohe Performance ist die vollständige Nutzung neuester Browser-Technologien.
1. WebGPU — GPU-Beschleunigung
WebGPU ist eine neue Web-API für Low-Level-GPU-Zugriff vom Browser. Im Gegensatz zum älteren WebGL ist es speziell für allgemeines GPU-Computing (GPGPU) konzipiert und ermöglicht hochgeschwindige Matrixoperationen, die für LLMs erforderlich sind.
Intern verwendet WebLLM Apache TVM und MLC-LLM, um Modell-Berechnungsgraphen für WebGPU zu optimieren. Modernste Inferenz-Optimierungstechniken wie PagedAttention und FlashAttention sind ebenfalls integriert.
Besonders bedeutsam ist der Vorteil der Geräte-Abstraktion. Herkömmliche native Implementierungen erforderten separate Codebasen für jeden Hersteller — CUDA (NVIDIA), Metal (Apple) usw. — aber mit WebGPU kann eine einzige Implementierung auf mehrere GPUs abzielen.
graph LR
A[Herkömmlicher Ansatz] --> B[CUDA-Implementierung]
A --> C[Metal-Implementierung]
A --> D[OpenCL-Implementierung]
A --> E[...]
F[WebLLM-Ansatz] --> G[Einzel-WebGPU für alle GPUs ✨]2. WebAssembly (Wasm) — CPU-Fallback
WebAssembly spielt eine wichtige Rolle, wenn keine GPU verfügbar ist oder für zusätzliche CPU-Berechnungen. Da es fortgeschrittenen in C/C++ geschriebenen Berechnungscode mit nahezu nativer Geschwindigkeit im Browser ausführen kann, behandelt es effizient bestimmte Modellverarbeitungen auf der CPU-Seite.
3. Web Workers — UI-Thread-Isolierung
LLM-Inferenz ist extrem ressourcenintensiv. Das Ausführen auf dem Hauptthread würde die UI einfrieren. WebLLM führt die Inferenzverarbeitung in einem Web Worker aus und hält so die Reaktionsfähigkeit der Benutzeroberfläche aufrecht.
graph LR
A[Hauptthread] <-->|Nachrichtenübermittlung| B[Web Worker]
A --> C[UI-Updates]
B --> D[LLM-Inferenz]4. Cache Storage — Schneller Start nach dem ersten Laden
LLM-Modelle sind typischerweise Hunderte von Megabytes bis mehrere Gigabytes groß. WebLLM speichert heruntergeladene Modelle in der Cache Storage des Browsers, sodass nachfolgende Starts sofort aus dem Cache laden.
Architekturübersicht
WebLLMs Architektur besteht aus drei Hauptkomponenten.
graph TB
A[Web-Anwendung<br/>OpenAI-ähnliche JavaScript-API]
B[MLCEngine Web Worker<br/>Verlagert schwere Inferenz vom UI-Thread]
C[WebGPU / WebAssembly<br/>GPU-Beschleunigung / CPU-Hilfsberechnung]
A --> B
B --> CPerformance
Gemäß den Evaluierungsergebnissen des Papers „WebLLM: A High-Performance In-Browser LLM Inference Engine" (arXiv:2412.15803):
Beim Vergleich von WebLLM (WebGPU + JavaScript/Wasm) mit MLC-LLM (Metal + Python/C++) auf einem Apple MacBook Pro M3 Max behielt WebLLM bis zu 80% der nativen Dekodierungsgeschwindigkeit bei.
Obwohl es im Browser läuft, zeigt das Erreichen von bis zu 80% der nativen Performance, dass es ein praktisches Nutzungsniveau erreicht hat.
Unterstützte Modelle
WebLLM unterstützt eine breite Palette von Modellen (ausgewählte Beispiele):
- Llama 3.1 / 3.2 Serie
- Phi 3.5 / 4 Serie
- Gemma 2 Serie
- Mistral Serie
- Qwen 2.5 Serie
Mehrere Quantisierungsformate (wie q4f16_1 und q4f32_1) sind verfügbar, sodass Sie basierend auf der Speicherkapazität Ihres Geräts wählen können.
Implementierung
Ich habe eine Chat-Anwendung mit WebLLM entwickelt. Hier ist ein Screenshot davon in Aktion:
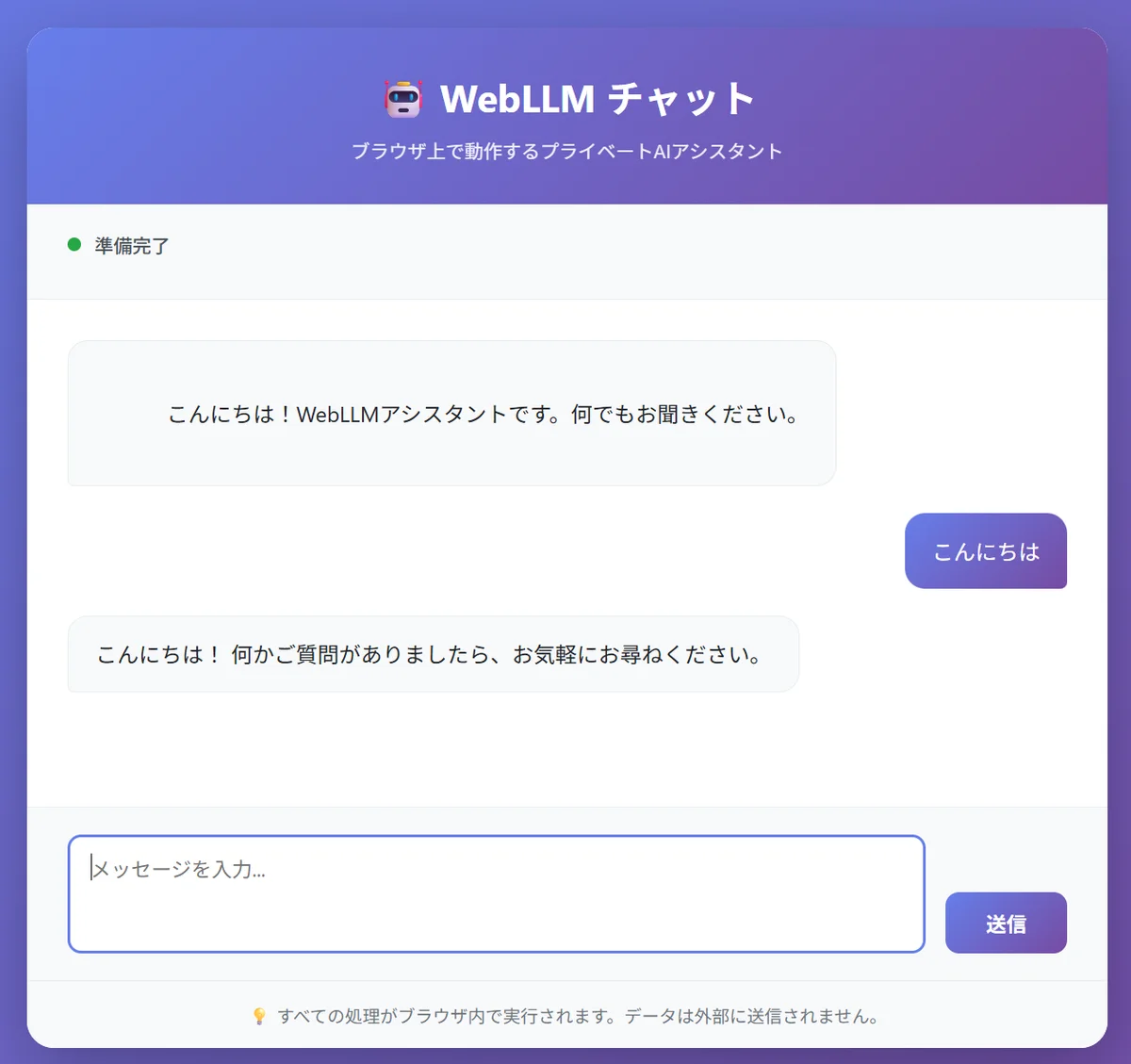
Ein privater KI-Assistent, der vollständig im Browser läuft. Alle Verarbeitungen werden lokal ausgeführt.
Lassen Sie uns durchgehen, wie man eine solche Anwendung implementiert.
Installation
npm install @mlc-ai/web-llm
Grundlegende Chat-Implementierung
import * as webllm from "@mlc-ai/web-llm";
async function main() {
// Modell auswählen (quantisiert)
const selectedModel = "Llama-3.2-3B-Instruct-q4f16_1-MLC";
// Engine initialisieren (Download-Fortschritt über Callback)
const engine = await webllm.CreateMLCEngine(selectedModel, {
initProgressCallback: (progress) => {
console.log(`Loading: ${Math.round(progress.progress * 100)}%`);
},
});
// Chat mit der OpenAI-kompatiblen API
const reply = await engine.chat.completions.create({
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Tell me about WebLLM." },
],
});
console.log(reply.choices[0].message.content);
}
main();
Web-Worker-Implementierung (Empfohlen)
Um UI-Einfrierungen zu verhindern, wird die Verwendung von Web Workers in der Produktion empfohlen.
import * as webllm from "@mlc-ai/web-llm";
const handler = new webllm.WebWorkerMLCEngineHandler();
self.onmessage = (msg) => {
handler.onmessage(msg);
};
import * as webllm from "@mlc-ai/web-llm";
const selectedModel = "Llama-3.2-3B-Instruct-q4f16_1-MLC";
// Web-Worker-Engine erstellen
const engine = new webllm.WebWorkerMLCEngine(
new Worker(new URL("./worker.js", import.meta.url), { type: "module" })
);
// Fortschritts-Callback einrichten
engine.setInitProgressCallback((progress) => {
console.log(`Loading: ${Math.round(progress.progress * 100)}%`);
});
// Modell laden
await engine.reload(selectedModel);
// Dann einfach engine.chat.completions.create() wie gewohnt aufrufen
Streaming-Unterstützung
const stream = await engine.chat.completions.create({
messages: [{ role: "user", content: "Tell me about Mount Fuji" }],
stream: true,
});
for await (const chunk of stream) {
const delta = chunk.choices[0]?.delta?.content ?? "";
process.stdout.write(delta); // Echtzeit-Ausgabe
}
Einschränkungen und Grenzen
Obwohl WebLLM eine sehr überzeugende Technologie ist, ist es wichtig, seine aktuellen Grenzen zu verstehen.
WebGPU-Browser-Unterstützung (Stand Februar 2026): Die Situation verbesserte sich bis Ende 2025 erheblich, und jetzt haben alle vier großen Browser — Chrome, Edge, Firefox und Safari — WebGPU standardmäßig aktiviert. Die Unterstützung variiert jedoch je nach Plattform.
| Browser | Desktop | Mobilgerät |
|---|---|---|
| Chrome / Edge | ✅ Vollständig in Stable unterstützt (v113+) | ✅ Android 12+-Geräte unterstützt |
| Firefox | ✅ Windows (v141+), macOS Apple Silicon (v145+) | ⚠️ Android-Unterstützung für 2026 erwartet |
| Safari | ✅ macOS / iOS / iPadOS 26+ | ✅ iOS 26+ |
Da die Unterstützung auch vom GPU-Hardware- und Treiberstatus abhängt, werden Feature-Erkennung über navigator.gpu und eine WebAssembly-Fallback-Implementierung weiterhin empfohlen.
Hardware-Beschleunigungseinstellungen
Selbst auf GPU-ausgestatteten Maschinen können Browser-Einstellungen das Rendering auf den Software-Modus beschränken. Wenn WebGPU „Software only" bei chrome://gpu anzeigt:
- Hardware-Beschleunigung aktivieren: Aktivieren Sie „Hardware-Beschleunigung verwenden, wenn möglich" unter
chrome://settings/system - GPU-Sperrliste deaktivieren: Aktivieren Sie „Software-Rendering-Liste überschreiben" in
chrome://flags - Browser vollständig neu starten: Alle Fenster schließen, bevor Sie ihn neu starten
Überprüfen Sie nach der Konfiguration, dass der WebGPU-Status „Hardware accelerated" bei chrome://gpu anzeigt.
Schwerer erster Download
Modelle müssen beim ersten Start heruntergeladen werden. Selbst die quantisierte Version von Llama-3.2-3B ist etwa 2–3 GB groß, was die Implementierung eines Fortschrittsanzeigers für eine gute Benutzererfahrung unerlässlich macht.
Modelle werden nicht über Origins hinweg geteilt
Gecachte Modelle werden nur innerhalb derselben Origin geteilt. Die Verwendung desselben Modells in einer anderen Web-App erfordert einen separaten Download.
LLM-Ausgabe bereinigen
Das direkte Einfügen von generiertem Text in das DOM birgt XSS-Risiken. Bereinigen Sie immer die Ausgabe mit Bibliotheken wie DOMPurify.
// ❌ Gefährlich
element.innerHTML = llmOutput;
// ✅ Sicher
element.innerHTML = DOMPurify.sanitize(llmOutput);
Anwendungsfälle
Hier sind Szenarien, in denen WebLLM besonders effektiv ist.
Datenschutzorientierte Anwendungen
In Bereichen, die sensible Informationen verarbeiten — wie Gesundheitswesen, Recht und Finanzen — ist es entscheidend, dass keine Daten in die Cloud gesendet werden. WebLLM schließt alle Verarbeitungen auf dem Gerät ab.
Offline-fähige Anwendungen
Sobald das Modell heruntergeladen ist, können KI-Funktionen ohne Internetverbindung bereitgestellt werden. In Kombination mit PWA können Sie KI-Assistenten entwickeln, die offline funktionieren.
Kosteneinsparung
Da API-Aufrufgebühren entfallen, können erhebliche Kosteneinsparungen für Anwendungen mit hoher Nutzung erwartet werden.
Hybride Inferenz
Eine hybride Architektur — WebLLM im Browser für leichte Aufgaben und Cloud-APIs für schwerere — ist ebenfalls ein effektiver Ansatz.
Ausblick
Die WebGPU-Spezifikation entwickelt sich weiter, und die Ergänzung neuer Funktionen wie Subgroups wird voraussichtlich weitere Performance-Verbesserungen bringen. Verbesserte Unterstützung für Apples Silicon Metal-Backend und Mobilgeräte wird ebenfalls erwartet.
Da Browser zu reifen Edge-KI-Ausführungsumgebungen werden, ist WebLLM bereit, eine Standardwahl für die Entwicklung datenschutsorientierter KI-Anwendungen zu werden.
Zusammenfassung
| Element | Details |
|---|---|
| Übersicht | Hochleistungs-LLM-Inferenz-Engine im Browser |
| Technologie-Stack | WebGPU + WebAssembly + Web Workers |
| Performance | Bis zu 80% der nativen Performance |
| Hauptvorteile | Datenschutz, Offline-Unterstützung, serverlos |
| Installation | npm install @mlc-ai/web-llm |