
はじめに
「LLMを使いたいけど、APIキーの管理が面倒……」「ユーザーの入力をクラウドに送りたくない……」
そんな悩みを一気に解決するのが WebLLM です。
WebLLM は、サーバーレス・バックエンドレスでブラウザ上にLLMを直接動かすことができる高性能な推論エンジンです。ChatGPT や Claude のようなクラウド型 AI とは異なり、推論処理のすべてがユーザーのデバイス上で完結します。
本記事では WebLLM の仕組み・特徴・実装方法を丁寧に解説します。
WebLLM とは
WebLLM(@mlc-ai/web-llm)は、MLC-AI プロジェクトが開発するオープンソースの JavaScript ライブラリです。Carnegie Mellon University・Shanghai Jiao Tong University・NVIDIA の研究者らが中心となって開発されており、2024年末に論文 "WebLLM: A High-Performance In-Browser LLM Inference Engine" として発表されました。
一言でいえば、
「ブラウザを LLM のランタイム環境にする」 フレームワーク
です。
何がすごいのか
| 特徴 | 内容 |
|---|---|
| 🌐 完全インブラウザ | サーバー不要。インストール不要 |
| 🔒 プライバシー保護 | データがデバイスの外に出ない |
| ⚡ WebGPU アクセラレーション | ネイティブ性能の70〜88%を達成 |
| 🔄 OpenAI 互換 API | 既存コードをほぼそのまま流用可能 |
| 📦 多様なモデル対応 | Llama・Phi・Gemma・Mistral など |
技術的な仕組み
WebLLM が高性能を実現できる理由は、ブラウザの最新技術をフル活用しているからです。
1. WebGPU — GPU アクセラレーション
WebGPU は、ブラウザから GPU に低レベルでアクセスするための新しい Web API です。従来の WebGL とは異なり、汎用 GPU 計算(GPGPU)に特化した設計となっており、LLM の行列演算を高速に処理できます。
WebLLM は内部で Apache TVM と MLC-LLM を使い、モデルの計算グラフを WebGPU 向けに最適化します。PagedAttention や FlashAttention といった最新の推論最適化技術も取り込まれています。
さらに重要なのが、デバイス抽象化の恩恵です。従来のネイティブ実装では CUDA(NVIDIA)や Metal(Apple)などベンダーごとに実装が必要でしたが、WebGPU を使えば単一の実装で複数 GPU に対応できます。
graph LR
A[従来のアプローチ] --> B[CUDA実装]
A --> C[Metal実装]
A --> D[OpenCL実装]
A --> E[...]
F[WebLLMのアプローチ] --> G[WebGPU 1つで全GPU対応 ✨]2. WebAssembly (Wasm) — CPU フォールバック
GPU が使えない場面や CPU での補助計算には、WebAssembly が活躍します。C/C++ で書かれた高度な計算コードをブラウザ上でネイティブに近い速度で実行できるため、モデルの一部処理を CPU 側で効率よくこなします。
3. Web Worker — UI スレッドの分離
LLM の推論は非常に重い処理です。これをメインスレッドで実行すると UI がフリーズしてしまいます。WebLLM は Web Worker 上で推論処理を動かすことで、ユーザーインターフェースの応答性を維持します。
graph LR
A[メインスレッド] <-->|メッセージ送受信| B[Web Worker]
A --> C[UI 更新]
B --> D[LLM 推論処理]4. Cache Storage — 初回後の高速起動
LLM モデルは一般に数百 MB〜数 GB と大容量です。WebLLM は一度ダウンロードしたモデルをブラウザの Cache Storage に保存するため、2回目以降の起動はキャッシュから即座に読み込まれます。
アーキテクチャ全体像
WebLLM のアーキテクチャは主に3つのコンポーネントで構成されています。
graph TB
A[Web Application<br/>OpenAI-like JavaScript API]
B[MLCEngine Web Worker<br/>重い推論処理を UI スレッドから分離]
C[WebGPU / WebAssembly<br/>GPU加速 / CPU補助計算]
A --> B
B --> Cパフォーマンス
論文 "WebLLM: A High-Performance In-Browser LLM Inference Engine" (arXiv:2412.15803) による評価結果によると、
Apple MacBook Pro M3 Max 上で WebLLM(WebGPU + JavaScript/Wasm)と MLC-LLM(Metal + Python/C++)を比較した結果、WebLLM はネイティブのデコード速度の 最大 80% を保持しました。
ブラウザ上での実行でありながら、ネイティブ性能の最大 80% という高いパフォーマンスを達成しており、実用レベルに達していることがわかります。
対応モデル
WebLLM は幅広いモデルをサポートしています(一部抜粋)。
- Llama 3.1 / 3.2 シリーズ
- Phi 3.5 / 4 シリーズ
- Gemma 2 シリーズ
- Mistral シリーズ
- Qwen 2.5 シリーズ
量子化形式(q4f16_1、q4f32_1 など)も複数用意されており、デバイスのメモリに合わせて選択できます。
実装してみよう
実際に WebLLM を使ってチャットアプリケーションを作成しました。以下は動作中のスクリーンショットです:
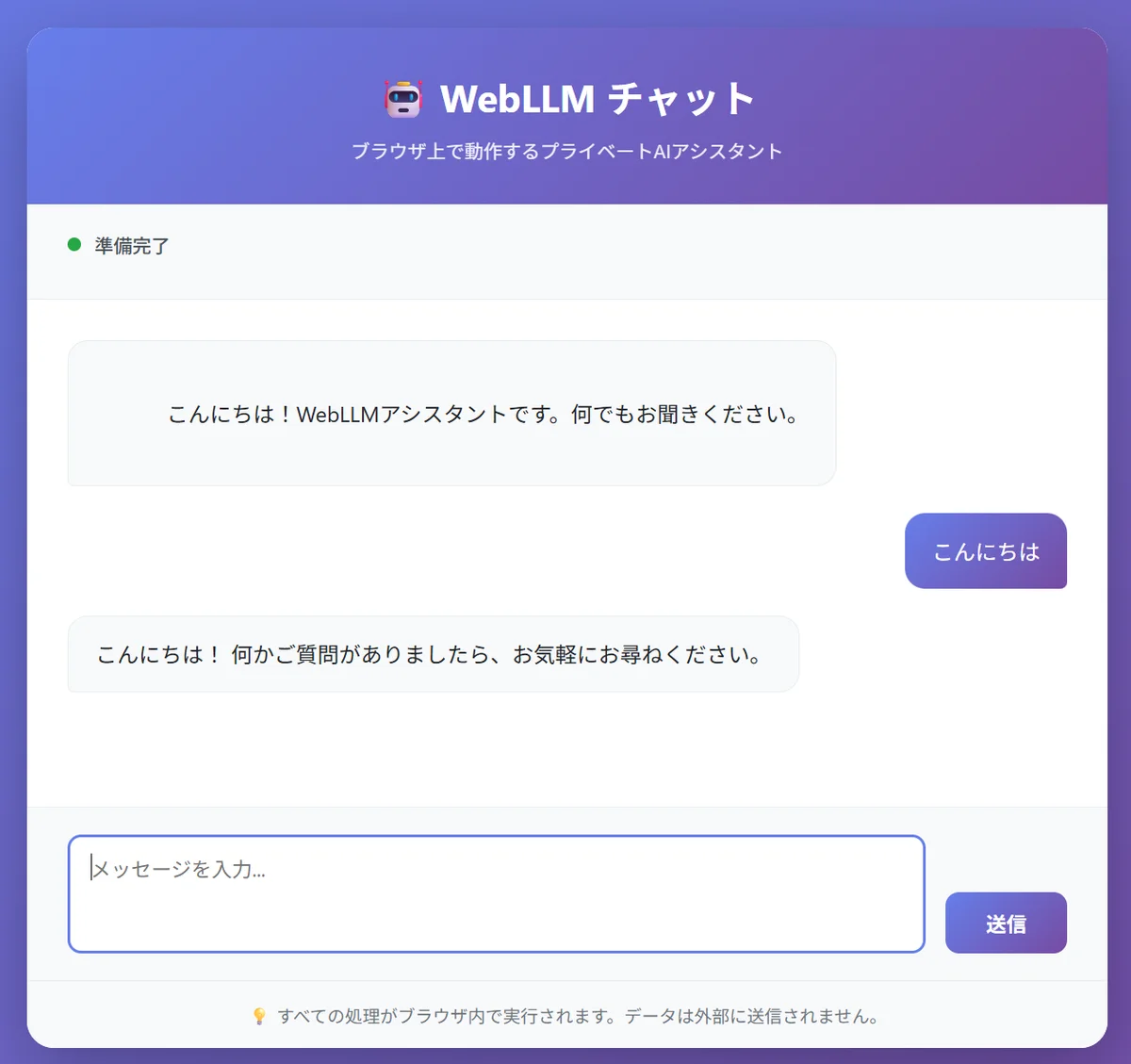
ブラウザ上で完結するプライベートAIアシスタント。すべての処理がローカルで実行されます。
それでは、このようなアプリケーションの実装方法を見ていきましょう。
インストール
npm install @mlc-ai/web-llm
基本的なチャット実装
import * as webllm from "@mlc-ai/web-llm";
async function main() {
// モデルを選択(量子化済み)
const selectedModel = "Llama-3.2-3B-Instruct-q4f16_1-MLC";
// エンジン初期化(ダウンロード進捗をコールバックで受け取れる)
const engine = await webllm.CreateMLCEngine(selectedModel, {
initProgressCallback: (progress) => {
console.log(`Loading: ${Math.round(progress.progress * 100)}%`);
},
});
// OpenAI 互換 API でチャット
const reply = await engine.chat.completions.create({
messages: [
{ role: "system", content: "あなたは親切なアシスタントです。" },
{ role: "user", content: "WebLLMについて教えてください。" },
],
});
console.log(reply.choices[0].message.content);
}
main();
Web Worker を使った実装(推奨)
UIのフリーズを防ぐために、本番では Web Worker での実装が推奨されます。
import * as webllm from "@mlc-ai/web-llm";
const handler = new webllm.WebWorkerMLCEngineHandler();
self.onmessage = (msg) => {
handler.onmessage(msg);
};
import * as webllm from "@mlc-ai/web-llm";
const selectedModel = "Llama-3.2-3B-Instruct-q4f16_1-MLC";
// Web Worker エンジンを作成
const engine = new webllm.WebWorkerMLCEngine(
new Worker(new URL("./worker.js", import.meta.url), { type: "module" })
);
// 進捗コールバックを設定
engine.setInitProgressCallback((progress) => {
console.log(`Loading: ${Math.round(progress.progress * 100)}%`);
});
// モデルを読み込む
await engine.reload(selectedModel);
// あとは通常通り engine.chat.completions.create() を呼ぶだけ
ストリーミング対応
const stream = await engine.chat.completions.create({
messages: [{ role: "user", content: "富士山について教えて" }],
stream: true,
});
for await (const chunk of stream) {
const delta = chunk.choices[0]?.delta?.content ?? "";
process.stdout.write(delta); // リアルタイム表示
}
注意点・制限事項
WebLLM は非常に魅力的な技術ですが、現時点での制限も把握しておきましょう。
ハードウェアアクセラレーションの設定
GPU搭載機でもブラウザの設定によりソフトウェアレンダリングに制限されることがあります。chrome://gpu でWebGPUが "Software only" になっている場合:
- ハードウェアアクセラレーションを有効化:
chrome://settings/systemで「ハードウェア アクセラレーションが使用可能な場合は使用する」をオンにする - GPUブロックリストを無効化:
chrome://flagsで "Override software rendering list" を Enabled にする - ブラウザを完全に再起動:すべてのウィンドウを閉じてから起動
設定後、chrome://gpu で WebGPU のステータスが "Hardware accelerated" になっていることを確認してください。
初回ダウンロードが重い
モデルは初回起動時にダウンロードが必要です。Llama-3.2-3B の量子化版でも 2〜3 GB 程度になるため、ユーザー体験を考慮した進捗表示の実装が欠かせません。
オリジン間でモデルは共有されない
キャッシュしたモデルは同一オリジン内でしか共有されません。別のウェブアプリで同じモデルを使う場合は再ダウンロードが必要です。
LLM 出力のサニタイズ
生成テキストをそのまま DOM に挿入することは XSS のリスクがあります。DOMPurify 等を使った出力のサニタイズを必ず行いましょう。
// ❌ 危険
element.innerHTML = llmOutput;
// ✅ 安全
element.innerHTML = DOMPurify.sanitize(llmOutput);
ユースケース
WebLLM が特に有効なシナリオを整理します。
プライバシー重視のアプリケーション
医療・法律・金融など、機密性の高い情報を扱う場面では、データをクラウドに送信しないことが重要です。WebLLM はすべての処理をデバイス内で完結させます。
オフライン対応のアプリケーション
一度モデルをダウンロードすれば、インターネット接続なしでも AI 機能を提供できます。PWA と組み合わせることで、オフラインでも動作する AI アシスタントを構築できます。
コスト削減
API 呼び出し料金が不要になるため、使用頻度が高いアプリケーションでは大幅なコスト削減が期待できます。
ハイブリッド推論
軽いタスクはブラウザ内の WebLLM で、重いタスクはクラウド API で、というハイブリッドアーキテクチャも有効です。
今後の展望
WebGPU の仕様は現在も進化中であり、シャッフリングなどの新機能が追加されることでさらなる高速化が見込まれています。また Apple Silicon の Metal バックエンドや、モバイル端末への対応強化も期待されます。
ブラウザがエッジ AI の実行環境として成熟することで、WebLLM はプライバシーファーストな AI アプリケーション開発の標準的な選択肢になっていくでしょう。
まとめ
| 項目 | 内容 |
|---|---|
| 概要 | ブラウザ上で動作する高性能 LLM 推論エンジン |
| 技術基盤 | WebGPU + WebAssembly + Web Worker |
| パフォーマンス | ネイティブ性能の最大 80% |
| 主な利点 | プライバシー保護・オフライン対応・サーバーレス |
| インストール | npm install @mlc-ai/web-llm |
| API 互換性 | OpenAI 互換 |
WebLLM は「AI はクラウドで動くもの」という常識を塗り替えつつある技術です。まずは公式のデモ(WebLLM Chat)でブラウザ内 LLM を体験してみてください。