
소개
"LLM을 사용하고 싶은데 API 키 관리가 귀찮아…" "사용자 입력을 클라우드에 보내고 싶지 않아…"
WebLLM은 이 두 가지 문제를 동시에 해결합니다.
WebLLM은 서버리스·백엔드 불필요로 LLM을 브라우저에서 직접 실행하는 고성능 추론 엔진입니다. ChatGPT나 Claude 같은 클라우드 기반 AI 서비스와 달리, 모든 추론 처리가 사용자의 디바이스에서 완결됩니다.
이 글에서는 WebLLM의 아키텍처, 기능, 구현 방법을 자세하게 설명합니다.
WebLLM이란?
WebLLM (@mlc-ai/web-llm)은 MLC-AI 프로젝트에서 개발한 오픈소스 JavaScript 라이브러리입니다. 주로 카네기멜론대, 상하이교통대, NVIDIA 연구자들이 구축했으며, 2024년 말 논문 "WebLLM: A High-Performance In-Browser LLM Inference Engine"으로 발표되었습니다.
한마디로:
브라우저를 LLM의 런타임 환경으로 만드는 프레임워크입니다.
주요 기능
| 기능 | 설명 |
|---|---|
| 🌐 완전 브라우저 내 실행 | 서버 불필요. 설치 불필요 |
| 🔒 프라이버시 보호 | 데이터가 디바이스 밖으로 나가지 않음 |
| ⚡ WebGPU 가속 | 네이티브 성능의 70~88% 달성 |
| 🔄 OpenAI 호환 API | 최소한의 변경으로 기존 코드를 재사용 가능 |
| 📦 폭넓은 모델 지원 | Llama, Phi, Gemma, Mistral 등 |
동작 원리
WebLLM이 고성능을 발휘하는 이유는 최신 브라우저 기술을 완전히 활용하기 때문입니다.
1. WebGPU — GPU 가속
WebGPU는 브라우저에서 저수준 GPU 접근을 위한 새로운 Web API입니다. 기존의 WebGL과 달리 범용 GPU 컴퓨팅(GPGPU)을 위해 설계되어 LLM에 필요한 고속 행렬 연산이 가능합니다.
내부적으로 WebLLM은 Apache TVM과 MLC-LLM을 사용해 모델 계산 그래프를 WebGPU에 최적화합니다. PagedAttention, FlashAttention 같은 최첨단 추론 최적화 기법도 도입되어 있습니다.
특히 중요한 것은 디바이스 추상화의 혜택입니다. 기존 네이티브 구현에서는 벤더별로 별도의 코드베이스(CUDA(NVIDIA), Metal(Apple) 등)가 필요했지만, WebGPU에서는 단일 구현으로 여러 GPU를 대상으로 할 수 있습니다.
graph LR
A[기존 접근 방식] --> B[CUDA 구현]
A --> C[Metal 구현]
A --> D[OpenCL 구현]
A --> E[...]
F[WebLLM 접근 방식] --> G[Single WebGPU for All GPUs ✨]2. WebAssembly (Wasm) — CPU 폴백
WebAssembly는 GPU를 사용할 수 없을 때나 보조 CPU 계산에 중요한 역할을 합니다. C/C++로 작성된 고급 계산 코드를 브라우저에서 네이티브에 가까운 속도로 실행할 수 있어 CPU 측의 특정 모델 처리를 효율적으로 처리합니다.
3. Web Workers — UI 스레드 격리
LLM 추론은 극도로 리소스 집약적입니다. 메인 스레드에서 실행하면 UI가 멈춥니다. WebLLM은 Web Worker에서 추론 처리를 실행해 사용자 인터페이스의 응답성을 유지합니다.
graph LR
A[메인 스레드] <-->|메시지 패싱| B[Web Worker]
A --> C[UI 업데이트]
B --> D[LLM 추론]4. Cache Storage — 첫 로딩 후 빠른 시작
LLM 모델은 일반적으로 수백 MB에서 수 GB 크기입니다. WebLLM은 다운로드한 모델을 브라우저의 Cache Storage에 저장하므로, 이후 실행 시 캐시에서 즉시 로드됩니다.
아키텍처 개요
WebLLM의 아키텍처는 세 가지 주요 컴포넌트로 구성됩니다.
graph TB
A[웹 애플리케이션<br/>OpenAI 유사 JavaScript API]
B[MLCEngine Web Worker<br/>UI 스레드에서 무거운 추론을 오프로드]
C[WebGPU / WebAssembly<br/>GPU 가속 / CPU 보조 계산]
A --> B
B --> C성능
논문 "WebLLM: A High-Performance In-Browser LLM Inference Engine" (arXiv:2412.15803)의 평가 결과에 따르면:
Apple MacBook Pro M3 Max에서 WebLLM (WebGPU + JavaScript/Wasm)과 MLC-LLM (Metal + Python/C++)을 비교했을 때, WebLLM은 네이티브 디코딩 속도의 **최대 80%**를 유지했습니다.
브라우저에서 실행함에도 불구하고 네이티브 성능의 최대 80%를 달성한 것은 실용적인 수준에 도달했음을 보여줍니다.
지원 모델
WebLLM은 다양한 모델을 지원합니다(일부 예시):
- Llama 3.1 / 3.2 시리즈
- Phi 3.5 / 4 시리즈
- Gemma 2 시리즈
- Mistral 시리즈
- Qwen 2.5 시리즈
여러 양자화 형식(q4f16_1, q4f32_1 등)을 사용할 수 있어 디바이스의 메모리 용량에 따라 선택 가능합니다.
구현
WebLLM을 사용해 채팅 애플리케이션을 만들었습니다. 동작 중인 스크린샷입니다:
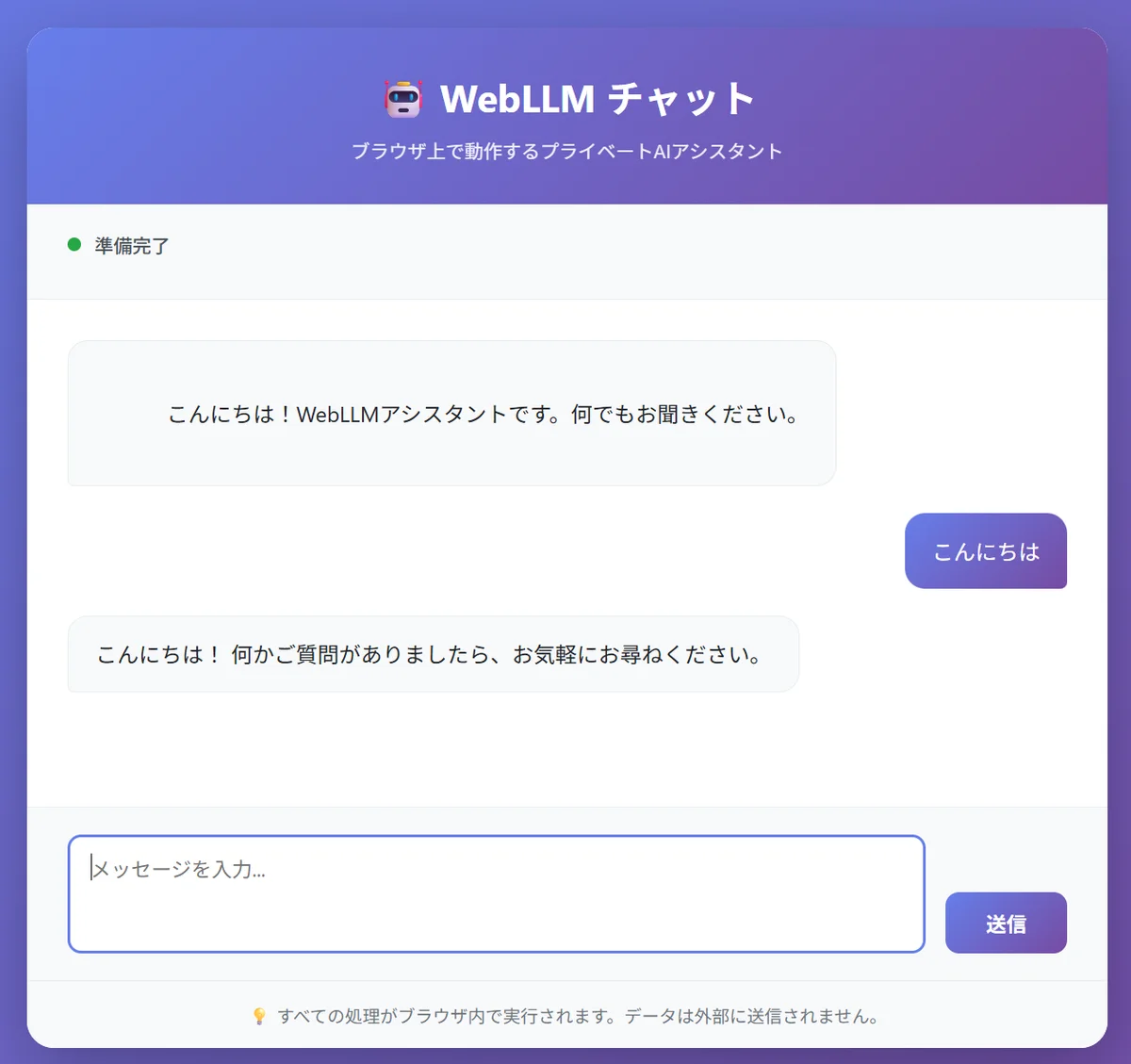
브라우저에서 완전히 실행되는 프라이빗 AI 어시스턴트. 모든 처리가 로컬에서 실행됩니다.
이런 애플리케이션을 구현하는 방법을 살펴보겠습니다.
설치
npm install @mlc-ai/web-llm
기본 채팅 구현
import * as webllm from "@mlc-ai/web-llm";
async function main() {
// 모델 선택 (양자화됨)
const selectedModel = "Llama-3.2-3B-Instruct-q4f16_1-MLC";
// 엔진 초기화 (콜백으로 다운로드 진행 상황 표시)
const engine = await webllm.CreateMLCEngine(selectedModel, {
initProgressCallback: (progress) => {
console.log(`Loading: ${Math.round(progress.progress * 100)}%`);
},
});
// OpenAI 호환 API를 사용한 채팅
const reply = await engine.chat.completions.create({
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Tell me about WebLLM." },
],
});
console.log(reply.choices[0].message.content);
}
main();
Web Worker 구현 (권장)
프로덕션에서 UI 멈춤을 방지하려면 Web Workers 사용을 권장합니다.
import * as webllm from "@mlc-ai/web-llm";
const handler = new webllm.WebWorkerMLCEngineHandler();
self.onmessage = (msg) => {
handler.onmessage(msg);
};
import * as webllm from "@mlc-ai/web-llm";
const selectedModel = "Llama-3.2-3B-Instruct-q4f16_1-MLC";
// Web Worker 엔진 생성
const engine = new webllm.WebWorkerMLCEngine(
new Worker(new URL("./worker.js", import.meta.url), { type: "module" })
);
// 진행 상황 콜백 설정
engine.setInitProgressCallback((progress) => {
console.log(`Loading: ${Math.round(progress.progress * 100)}%`);
});
// 모델 로드
await engine.reload(selectedModel);
// 이후 engine.chat.completions.create()를 평소처럼 호출
스트리밍 지원
const stream = await engine.chat.completions.create({
messages: [{ role: "user", content: "후지산에 대해 알려주세요" }],
stream: true,
});
for await (const chunk of stream) {
const delta = chunk.choices[0]?.delta?.content ?? "";
process.stdout.write(delta); // 실시간 출력
}
주의사항 및 제한사항
WebLLM은 매우 매력적인 기술이지만, 현재의 제한사항을 이해하는 것이 중요합니다.
WebGPU 브라우저 지원 (2026년 2월 기준): 2025년 말까지 상황이 크게 개선되어 현재 Chrome, Edge, Firefox, Safari의 주요 4개 브라우저 모두에서 WebGPU가 기본적으로 활성화되어 있습니다. 단, 지원 상황은 플랫폼에 따라 다릅니다.
| 브라우저 | 데스크톱 | 모바일 |
|---|---|---|
| Chrome / Edge | ✅ 안정 버전(v113+)에서 완전 지원 | ✅ Android 12+ 기기에서 지원 |
| Firefox | ✅ Windows (v141+), macOS Apple Silicon (v145+) | ⚠️ Android 지원은 2026년 예정 |
| Safari | ✅ macOS / iOS / iPadOS 26+ | ✅ iOS 26+ |
지원은 GPU 하드웨어 및 드라이버 상태에도 의존하므로, navigator.gpu를 통한 기능 감지와 WebAssembly 폴백 구현이 여전히 권장됩니다.
하드웨어 가속 설정
GPU가 장착된 기기라도 브라우저 설정에 따라 렌더링이 소프트웨어 모드로 제한될 수 있습니다. chrome://gpu에서 WebGPU가 "Software only"로 표시되는 경우:
- 하드웨어 가속 활성화:
chrome://settings/system에서 "사용 가능한 경우 하드웨어 가속 사용"을 켬 - GPU 차단 목록 비활성화:
chrome://flags에서 "Override software rendering list" 활성화 - 브라우저 완전 재시작: 모든 창을 닫고 다시 실행
설정 후 chrome://gpu에서 WebGPU 상태가 "Hardware accelerated"로 표시되는지 확인합니다.
첫 실행 시 대용량 다운로드
모델은 첫 실행 시 다운로드해야 합니다. 양자화된 Llama-3.2-3B도 약 2~3 GB이므로, 좋은 사용자 경험을 위해 진행 상황 표시기 구현이 필수입니다.
모델이 오리진 간에 공유되지 않음
캐시된 모델은 동일한 오리진 내에서만 공유됩니다. 다른 웹 앱에서 같은 모델을 사용하면 별도의 다운로드가 필요합니다.
LLM 출력 살균
생성된 텍스트를 DOM에 직접 삽입하면 XSS 위험이 있습니다. DOMPurify 같은 라이브러리를 사용해 항상 출력을 살균하세요.
// ❌ 위험
element.innerHTML = llmOutput;
// ✅ 안전
element.innerHTML = DOMPurify.sanitize(llmOutput);
활용 사례
WebLLM이 특히 효과적인 시나리오입니다.
프라이버시 중심 애플리케이션
의료, 법률, 금융 등 민감한 정보를 다루는 분야에서는 데이터가 클라우드로 전송되지 않는 것이 중요합니다. WebLLM은 모든 처리를 디바이스에서 완결합니다.
오프라인 지원 애플리케이션
모델이 다운로드되면 인터넷 연결 없이도 AI 기능을 제공할 수 있습니다. PWA와 결합하면 오프라인에서도 동작하는 AI 어시스턴트를 만들 수 있습니다.
비용 절감
API 호출 비용이 없어지므로 고사용량 애플리케이션에서 상당한 비용 절감을 기대할 수 있습니다.
하이브리드 추론
가벼운 작업에는 브라우저 내 WebLLM을, 무거운 작업에는 클라우드 API를 사용하는 하이브리드 아키텍처도 효과적인 접근 방식입니다.
향후 전망
WebGPU 사양은 계속 발전 중이며, subgroups 같은 새로운 기능 추가로 더 많은 성능 향상이 기대됩니다. Apple Silicon의 Metal 백엔드와 모바일 기기에 대한 지원 강화도 기대됩니다.
브라우저가 엣지 AI 실행 환경으로 성숙해 감에 따라, WebLLM은 프라이버시 우선 AI 애플리케이션 개발의 표준 선택지가 될 것으로 보입니다.
정리
| 항목 | 내용 |
|---|---|
| 개요 | 브라우저에서 실행되는 고성능 LLM 추론 엔진 |
| 기술 스택 | WebGPU + WebAssembly + Web Workers |
| 성능 | 네이티브 성능의 최대 80% |
| 주요 장점 | 프라이버시 보호, 오프라인 지원, 서버리스 |
| 설치 | npm install @mlc-ai/web-llm |
| API 호환성 | OpenAI 호환 |
WebLLM은 "AI는 클라우드에서 실행된다"는 상식을 바꾸고 있는 기술입니다. 공식 데모 WebLLM Chat에서 브라우저 내 LLM을 직접 체험해 보세요.